Are You Making These Deepseek Mistakes?
페이지 정보

본문

 DeepSeek first released DeepSeek-Coder, an open-source AI instrument designed for programming. The Chat variations of the two Base fashions was released concurrently, obtained by coaching Base by supervised finetuning (SFT) followed by direct coverage optimization (DPO). However the important level here is that Liang has discovered a way to construct competent models with few resources. DeepSeek R1 is such a creature (you possibly can access the model for your self right here). Janus-Pro surpasses earlier unified model and matches or exceeds the performance of task-specific fashions. For developers, high quality-tuning the AI models for specialized tasks is crucial. This example highlights that whereas giant-scale training remains costly, smaller, targeted high-quality-tuning efforts can nonetheless yield impressive results at a fraction of the cost. There are just a few AI coding assistants out there but most price cash to access from an IDE. The company notably didn’t say how much it price to train its mannequin, leaving out potentially expensive research and growth costs.
DeepSeek first released DeepSeek-Coder, an open-source AI instrument designed for programming. The Chat variations of the two Base fashions was released concurrently, obtained by coaching Base by supervised finetuning (SFT) followed by direct coverage optimization (DPO). However the important level here is that Liang has discovered a way to construct competent models with few resources. DeepSeek R1 is such a creature (you possibly can access the model for your self right here). Janus-Pro surpasses earlier unified model and matches or exceeds the performance of task-specific fashions. For developers, high quality-tuning the AI models for specialized tasks is crucial. This example highlights that whereas giant-scale training remains costly, smaller, targeted high-quality-tuning efforts can nonetheless yield impressive results at a fraction of the cost. There are just a few AI coding assistants out there but most price cash to access from an IDE. The company notably didn’t say how much it price to train its mannequin, leaving out potentially expensive research and growth costs.
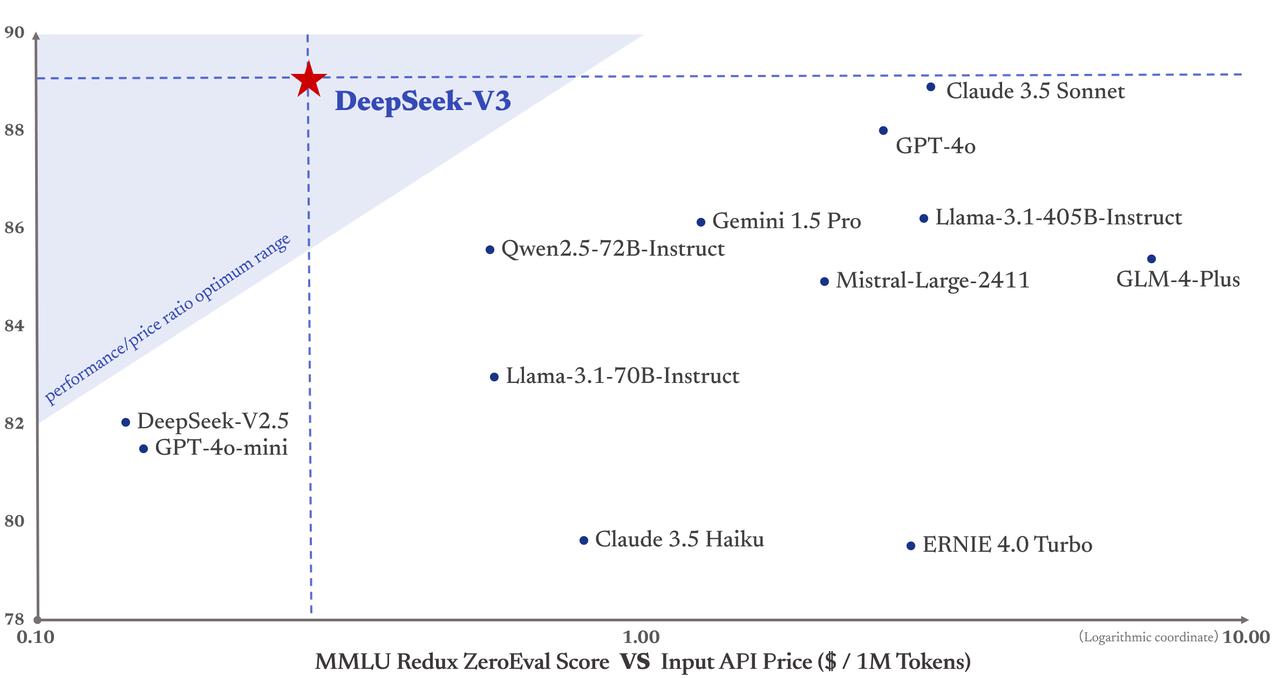
However, this came at the cost of some errors that popped up pretty usually for customers. "If DeepSeek’s cost numbers are actual, then now pretty much any giant organisation in any company can construct on and host it," Tim Miller, a professor specialising in AI on the University of Queensland, instructed Al Jazeera. Eight GPUs are required. What are the key options of DeepSeek’s language fashions? The Deepseek Online chat online-Coder-V2 paper introduces a significant advancement in breaking the barrier of closed-source fashions in code intelligence. U.S. dominance in synthetic intelligence. All of these programs achieved mastery in its personal space by means of self-coaching/self-play and by optimizing and maximizing the cumulative reward over time by interacting with its atmosphere where intelligence was noticed as an emergent property of the system. At a minimum, let’s not hearth off a starting gun to a race that we'd properly not win, even when all of humanity wasn’t very prone to lose it, over a ‘missile gap’ type lie that we are somehow not at the moment in the lead. While Musk and Altman have been publicly feuding for years-Musk truly was certainly one of OpenAI’s cofounders and has sued the corporate over its plans to change into a for-profit entity-this move could signify a much deeper blow.
Within the second stage, these experts are distilled into one agent utilizing RL with adaptive KL-regularization. So what are you waiting for? Sure, challenges like regulation and increased competition lie ahead, however these are extra rising pains than roadblocks. Likewise, if you purchase one million tokens of V3, it’s about 25 cents, in comparison with $2.50 for 4o. Doesn’t that mean that the DeepSeek fashions are an order of magnitude more efficient to run than OpenAI’s? ????Crafted with 2 trillion bilingual tokens. 텍스트를 단어나 형태소 등의 ‘토큰’으로 분리해서 처리한 후 수많은 계층의 계산을 해서 이 토큰들 간의 관계를 이해하는 ‘트랜스포머 아키텍처’가 DeepSeek-V2의 핵심으로 근간에 자리하고 있습니다. DeepSeek-V2의 MoE는 위에서 살펴본 DeepSeekMoE와 같이 작동합니다. 자, 이제 DeepSeek-V2의 장점, 그리고 남아있는 한계들을 알아보죠. 자, 그리고 2024년 8월, 바로 며칠 전 가장 따끈따끈한 신상 모델이 출시되었는데요. 그리고 2024년 3월 말, DeepSeek는 비전 모델에 도전해서 고품질의 비전-언어 이해를 하는 모델 DeepSeek-VL을 출시했습니다. 대부분의 오픈소스 비전-언어 모델이 ‘Instruction Tuning’에 집중하는 것과 달리, 시각-언어데이터를 활용해서 Pretraining (사전 훈련)에 더 많은 자원을 투입하고, 고해상도/저해상도 이미지를 처리하는 두 개의 비전 인코더를 사용하는 하이브리드 비전 인코더 (Hybrid Vision Encoder) 구조를 도입해서 성능과 효율성의 차별화를 꾀했습니다.
- 이전글The Death Of Vape Shop And The Way to Avoid It 25.02.22
- 다음글5 Unbelievable Vape Store Examples 25.02.22
댓글목록
등록된 댓글이 없습니다.