Addmeto (Addmeto) @ Tele.ga
페이지 정보

본문
 On this complete guide, we evaluate DeepSeek AI, ChatGPT, and Qwen AI, diving deep into their technical specs, options, use cases. The benchmark consists of artificial API operate updates paired with program synthesis examples that use the up to date performance. The CodeUpdateArena benchmark is designed to test how properly LLMs can replace their very own knowledge to sustain with these real-world changes. The paper presents a new benchmark referred to as CodeUpdateArena to test how nicely LLMs can replace their information to handle changes in code APIs. The paper presents the CodeUpdateArena benchmark to test how properly large language fashions (LLMs) can replace their data about code APIs that are continuously evolving. The benchmark involves synthetic API perform updates paired with program synthesis examples that use the up to date functionality, with the aim of testing whether or not an LLM can remedy these examples without being supplied the documentation for the updates. Succeeding at this benchmark would present that an LLM can dynamically adapt its knowledge to handle evolving code APIs, somewhat than being restricted to a fixed set of capabilities. Xin believes that whereas LLMs have the potential to accelerate the adoption of formal arithmetic, their effectiveness is restricted by the availability of handcrafted formal proof information.
On this complete guide, we evaluate DeepSeek AI, ChatGPT, and Qwen AI, diving deep into their technical specs, options, use cases. The benchmark consists of artificial API operate updates paired with program synthesis examples that use the up to date performance. The CodeUpdateArena benchmark is designed to test how properly LLMs can replace their very own knowledge to sustain with these real-world changes. The paper presents a new benchmark referred to as CodeUpdateArena to test how nicely LLMs can replace their information to handle changes in code APIs. The paper presents the CodeUpdateArena benchmark to test how properly large language fashions (LLMs) can replace their data about code APIs that are continuously evolving. The benchmark involves synthetic API perform updates paired with program synthesis examples that use the up to date functionality, with the aim of testing whether or not an LLM can remedy these examples without being supplied the documentation for the updates. Succeeding at this benchmark would present that an LLM can dynamically adapt its knowledge to handle evolving code APIs, somewhat than being restricted to a fixed set of capabilities. Xin believes that whereas LLMs have the potential to accelerate the adoption of formal arithmetic, their effectiveness is restricted by the availability of handcrafted formal proof information.
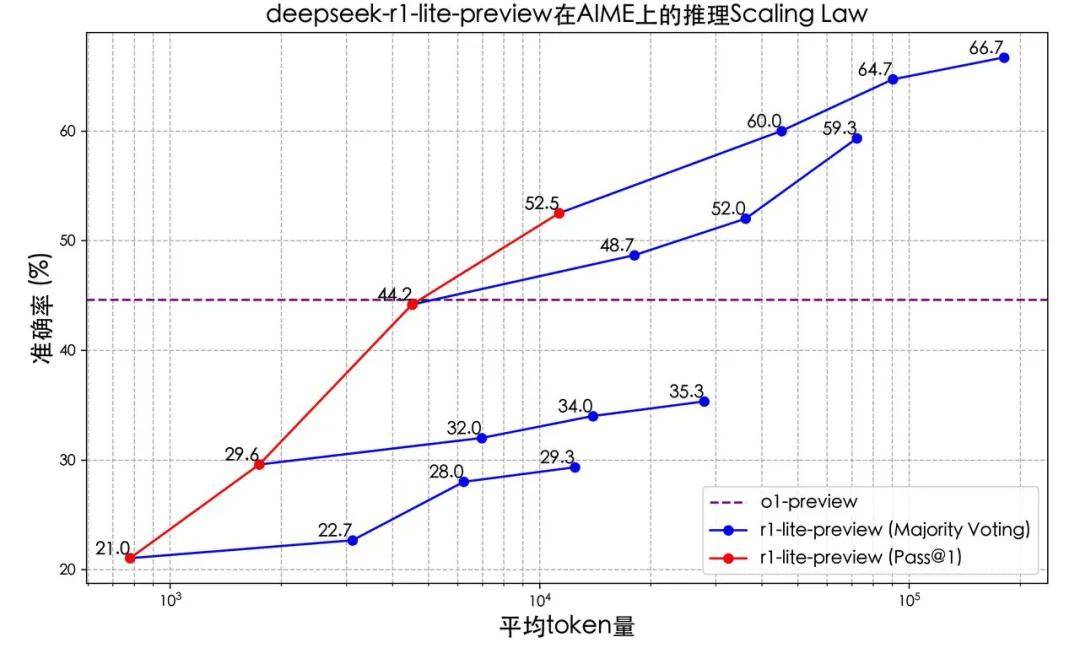 Meanwhile, Chinese companies are pursuing AI initiatives on their very own initiative-though typically with financing opportunities from state-led banks-in the hopes of capitalizing on perceived market potential. The results reveal excessive bypass/jailbreak rates, highlighting the potential dangers of those emerging attack vectors. Honestly, the results are unbelievable. Large language models (LLMs) are highly effective instruments that can be utilized to generate and understand code. It might probably have important implications for purposes that require looking over a vast space of potential solutions and have instruments to verify the validity of mannequin responses. By hosting the mannequin on your machine, you achieve higher management over customization, enabling you to tailor functionalities to your specific wants. With code, the model has to accurately reason about the semantics and habits of the modified perform, not just reproduce its syntax. That is extra challenging than updating an LLM's data about basic facts, as the model should reason concerning the semantics of the modified perform slightly than just reproducing its syntax. This paper examines how large language models (LLMs) can be utilized to generate and reason about code, however notes that the static nature of those models' knowledge does not mirror the truth that code libraries and APIs are continually evolving.
Meanwhile, Chinese companies are pursuing AI initiatives on their very own initiative-though typically with financing opportunities from state-led banks-in the hopes of capitalizing on perceived market potential. The results reveal excessive bypass/jailbreak rates, highlighting the potential dangers of those emerging attack vectors. Honestly, the results are unbelievable. Large language models (LLMs) are highly effective instruments that can be utilized to generate and understand code. It might probably have important implications for purposes that require looking over a vast space of potential solutions and have instruments to verify the validity of mannequin responses. By hosting the mannequin on your machine, you achieve higher management over customization, enabling you to tailor functionalities to your specific wants. With code, the model has to accurately reason about the semantics and habits of the modified perform, not just reproduce its syntax. That is extra challenging than updating an LLM's data about basic facts, as the model should reason concerning the semantics of the modified perform slightly than just reproducing its syntax. This paper examines how large language models (LLMs) can be utilized to generate and reason about code, however notes that the static nature of those models' knowledge does not mirror the truth that code libraries and APIs are continually evolving.
However, the information these fashions have is static - it doesn't change even as the precise code libraries and APIs they rely on are continually being up to date with new features and modifications. The DeepSeek-V3 model is skilled on 14.8 trillion high-high quality tokens and incorporates state-of-the-artwork options like auxiliary-loss-free Deep seek load balancing and multi-token prediction. The researchers evaluated their model on the Lean 4 miniF2F and FIMO benchmarks, which comprise a whole lot of mathematical problems. I suppose @oga needs to use the official Deepseek API service as an alternative of deploying an open-source model on their very own. You should use that menu to speak with the Ollama server with out needing a web UI. In case you are working the Ollama on another machine, it is best to have the ability to connect with the Ollama server port. In the models list, add the fashions that installed on the Ollama server you need to use within the VSCode. Send a test message like "hi" and verify if you can get response from the Ollama server. If you don't have Ollama put in, test the previous weblog.
We are going to make the most of the Ollama server, which has been beforehand deployed in our previous blog submit. In the example beneath, I'll outline two LLMs installed my Ollama server which is deepseek-coder and llama3.1. 2. Network access to the Ollama server. To make use of Ollama and Continue as a Copilot different, we'll create a Golang CLI app. If you do not have Ollama or one other OpenAI API-appropriate LLM, you'll be able to comply with the instructions outlined in that article to deploy and configure your individual instance. Why it matters: DeepSeek Chat is difficult OpenAI with a competitive giant language mannequin. The 7B model uses Multi-Head attention (MHA) while the 67B model makes use of Grouped-Query Attention (GQA). DeepSeek-Coder-V2 uses the identical pipeline as DeepSeekMath. Yet guaranteeing that data is preserved and obtainable shall be important. This self-hosted copilot leverages powerful language fashions to supply intelligent coding help whereas guaranteeing your information remains safe and beneath your control. A free self-hosted copilot eliminates the necessity for costly subscriptions or licensing charges associated with hosted solutions. Deepseek’s official API is compatible with OpenAI’s API, so just want so as to add a new LLM beneath admin/plugins/discourse-ai/ai-llms. To combine your LLM with VSCode, begin by installing the Continue extension that allow copilot functionalities.
- 이전글The Quickest & Best Method to Pod 25.02.22
- 다음글Drag: Do You actually Need It? This can Show you how To Decide! 25.02.22
댓글목록
등록된 댓글이 없습니다.