4 Stories You Didnt Find out about Deepseek China Ai
페이지 정보

본문
These transformer blocks are stacked such that the output of one transformer block results in the enter of the subsequent block. The router determines which tokens from the input sequence should be despatched to which specialists. The aforementioned CoT approach will be seen as inference-time scaling because it makes inference costlier via producing extra output tokens. 4. IDE Integrations: Announcement of quickly-to-come Visual Studio integration, increasing Cody's reach to extra developers. As the worldwide Free DeepSeek Ai Chat race heats up, this message turns into much more pressing. In that case, the message for individuals and organizations remains unchanged. Techniques like DeMo make it dramatically easier for federations of people and organizations to return together and train fashions to counterbalance this ‘big compute’ power. Researchers with Nous Research as well as Durk Kingma in an independent capacity (he subsequently joined Anthropic) have revealed Decoupled Momentum (DeMo), a "fused optimizer and knowledge parallel algorithm that reduces inter-accelerator communication necessities by a number of orders of magnitude." DeMo is part of a category of new technologies which make it far easier than before to do distributed coaching runs of giant AI techniques - instead of needing a single big datacenter to train your system, DeMo makes it potential to assemble a big virtual datacenter by piecing it collectively out of plenty of geographically distant computers.
 We’ve built-in MegaBlocks into LLM Foundry to enable scaling MoE coaching to hundreds of GPUs. A MoE mannequin is a model structure that makes use of a number of skilled networks to make predictions. The structure of a transformer-primarily based giant language mannequin sometimes consists of an embedding layer that leads into a number of transformer blocks (Figure 1, Subfigure A). Which means the mannequin has a higher capacity for studying, nevertheless, past a sure point the efficiency positive aspects tend to diminish. However, your complete mannequin must be loaded in reminiscence, not just the consultants getting used. However, if all tokens always go to the identical subset of consultants, training becomes inefficient and the other specialists find yourself undertrained. Compared to dense fashions, MoEs provide more efficient coaching for a given compute finances. It’s like TikTok but at a a lot grander scale and with extra precision. Over the past year, Mixture of Experts (MoE) models have surged in recognition, fueled by powerful open-source models like DBRX, Mixtral, Free DeepSeek v3, and lots of extra. Next week comes one other spate of necessary earnings experiences, headlined by the two different massive cloud players, Amazon and Alphabet, in addition to Palantir, NXP Semiconductor, Kyndryl, AMD, Qualcomm, Arm, Uber, Cloudflare and extra - full listing at the underside.
We’ve built-in MegaBlocks into LLM Foundry to enable scaling MoE coaching to hundreds of GPUs. A MoE mannequin is a model structure that makes use of a number of skilled networks to make predictions. The structure of a transformer-primarily based giant language mannequin sometimes consists of an embedding layer that leads into a number of transformer blocks (Figure 1, Subfigure A). Which means the mannequin has a higher capacity for studying, nevertheless, past a sure point the efficiency positive aspects tend to diminish. However, your complete mannequin must be loaded in reminiscence, not just the consultants getting used. However, if all tokens always go to the identical subset of consultants, training becomes inefficient and the other specialists find yourself undertrained. Compared to dense fashions, MoEs provide more efficient coaching for a given compute finances. It’s like TikTok but at a a lot grander scale and with extra precision. Over the past year, Mixture of Experts (MoE) models have surged in recognition, fueled by powerful open-source models like DBRX, Mixtral, Free DeepSeek v3, and lots of extra. Next week comes one other spate of necessary earnings experiences, headlined by the two different massive cloud players, Amazon and Alphabet, in addition to Palantir, NXP Semiconductor, Kyndryl, AMD, Qualcomm, Arm, Uber, Cloudflare and extra - full listing at the underside.
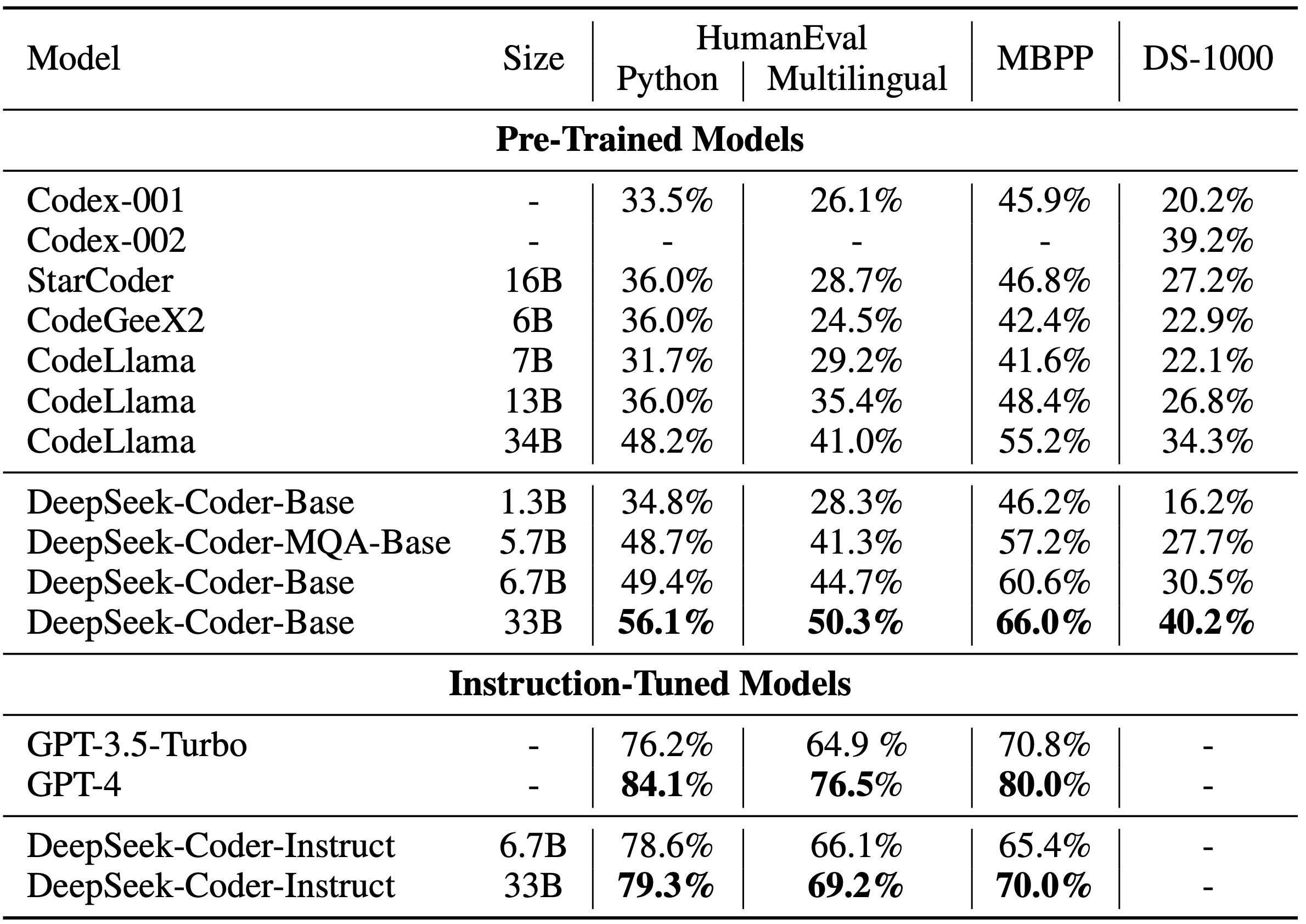 The 2 V2-Lite fashions were smaller, and trained equally. With PyTorch, we can successfully mix these two sorts of parallelism, leveraging FSDP’s higher level API while utilizing the decrease-degree DTensor abstraction once we wish to implement one thing custom like professional parallelism. In fact, using reasoning fashions for everything could be inefficient and expensive. As GPUs are optimized for giant-scale parallel computations, larger operations can higher exploit their capabilities, resulting in larger utilization and effectivity. This strategy permits us to stability reminiscence efficiency and communication value during large scale distributed coaching. Previous to MegaBlocks, dynamic routing formulations forced a tradeoff between model quality and hardware effectivity. To alleviate this problem, a load balancing loss is launched that encourages even routing to all consultants. This is typically accomplished by computing a gating rating for each token-professional pair, after which routing each token to the highest-scoring consultants. During training, the gating network adapts to assign inputs to the specialists, enabling the mannequin to specialize and improve its performance. The consultants themselves are typically applied as a feed forward network as well. It is because the gating community solely sends tokens to a subset of consultants, reducing the computational load.
The 2 V2-Lite fashions were smaller, and trained equally. With PyTorch, we can successfully mix these two sorts of parallelism, leveraging FSDP’s higher level API while utilizing the decrease-degree DTensor abstraction once we wish to implement one thing custom like professional parallelism. In fact, using reasoning fashions for everything could be inefficient and expensive. As GPUs are optimized for giant-scale parallel computations, larger operations can higher exploit their capabilities, resulting in larger utilization and effectivity. This strategy permits us to stability reminiscence efficiency and communication value during large scale distributed coaching. Previous to MegaBlocks, dynamic routing formulations forced a tradeoff between model quality and hardware effectivity. To alleviate this problem, a load balancing loss is launched that encourages even routing to all consultants. This is typically accomplished by computing a gating rating for each token-professional pair, after which routing each token to the highest-scoring consultants. During training, the gating network adapts to assign inputs to the specialists, enabling the mannequin to specialize and improve its performance. The consultants themselves are typically applied as a feed forward network as well. It is because the gating community solely sends tokens to a subset of consultants, reducing the computational load.
Instead of skilled weights being communicated throughout all GPUs, tokens are despatched to the gadget that incorporates the skilled. When a part of the mannequin is required for computation, it's gathered across all of the GPUs, and after the computation is complete, the gathered weights are discarded. While frontier models have already been used to help human scientists, e.g. for brainstorming ideas or writing code, DeepSeek online (https://www.fitday.com/fitness/forums/members/deepseek2.html) they still require in depth manual supervision or are heavily constrained to a particular task. This involves every system sending the tokens assigned to experts on different devices, whereas receiving tokens assigned to its local consultants. We first manually place experts on different GPUs, sometimes sharding throughout a node to ensure we are able to leverage NVLink for quick GPU communication once we route tokens. Correspondly, as we aggregate tokens throughout multiple GPUs, the scale of every matrix is proportionally bigger. Once the token-to-professional assignments are decided, an all-to-all communication step is carried out to dispatch the tokens to the devices hosting the relevant experts. Fault tolerance is essential for guaranteeing that LLMs could be educated reliably over prolonged periods, particularly in distributed environments where node failures are common. Customizability - Will be superb-tuned for specific duties or industries.
If you beloved this information along with you desire to obtain details with regards to DeepSeek Chat i implore you to stop by our web-page.
- 이전글These 5 Simple Drag Methods Will Pump Up Your Sales Nearly Instantly 25.02.22
- 다음글To People that Want To begin Disposable But Are Affraid To Get Started 25.02.22
댓글목록
등록된 댓글이 없습니다.